





There are many hashing algorithms to choose from. Here are the main factors to take into consideration when deciding which one is the best for you:
*speed: The algorithm reads the whole file to do some mathematical functions and generates a hash. A very computationally expensive algorithm may slow down the process.
*shortness of generated hash: This will save some space in the generated data stored in the database.
*security: The probability of two files having the same hash is called collision and can be very bad for our purposes, so it should be as near to zero as possible.
We should get a good balance between these three different factors. Usually, for secure hashing, you need a much more computationally expensive algorithm.
The 3 most used algorithms used for file hashing right now
MD5: The fastest and shortest generated hash (16 bytes). The probability of just two hashes accidentally colliding is approximately: 1.47*10-29.
SHA1: Is generally 20% slower than md5, the generated hash is a bit longer than MD5 (20 bytes). The probability of just two hashes accidentally colliding is approximately: 1*10-45
SHA256: The slowest, usually 60% slower than md5, and the longest generated hash (32 bytes). The probability of just two hashes accidentally colliding is approximately: 4.3*10-60.
As you can see, the slower and longer the hash is, the more reliable it is. But, as you can imagine, the probability of collision of hashes even for MD5 is terribly low. That probability is lower than the number of water drops contained in all the oceans of the earth together.
So the common sense tells you that the possibility of collision should not be considered as a factor because it looks like a very remote possibility. In the case of MD5 that is also true… at least for casual collisions.
Overview of the broken algorithm: MD5
As you probably know, MD5 has been compromised almost 20 years ago. So, nowadays it is actually possible to artificially produce MD5 collisions. All you need is time, hardware and the proper software.
Some time ago we got some samples with identical MD5 hash but different SHA256 and we were surprised. There was a possibility that it was a natural fortuity but as this seemed rather unlikely, we took a deeper look into the files. Here is what we found:
File A:
SHA256: 861F6D43AD5836D17FA1274E56E43B7E1C73499A6974FAAAF8ACEF96743D86F6
MD5: D8CD09CF87A064B91B6497123F62CA3D
SIZE: 619.648 byte

File B:
SHA256: C1F584DF922F94B5E7DF05A28508CD32A67DC92D682EAA35D468C62D179DFF50
MD5: D8CD09CF87A064B91B6497123F62CA3D
SIZE: 619.648 byte
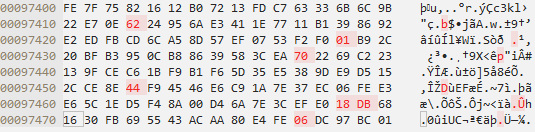
The files were so similar, only differing in 7 bytes, and they both produced the MD5 hash D8CD09CF87A064B91B6497123F62CA3D. The difference between the two samples is the leading bit in each nibble has been flipped. For example, the 20th byte (offset 0x97413) in the top sample (File A), 0xE2, is 11100010 in binary. The leading bit in the first nibble is flipped to make 01100010, which is 0x62 as shown in the lower sample (File B).
All that is needed to generate two colliding files is a template file with a 128-byte block of data, aligned on a 64-byte boundary that can be changed freely by the collision-finding algorithm.
Additionally, it was also discovered that it is possible to build collisions between two files with separately chosen prefixes. This technique was used in the creation of the rogue CA certificate in 2008.
For science!






